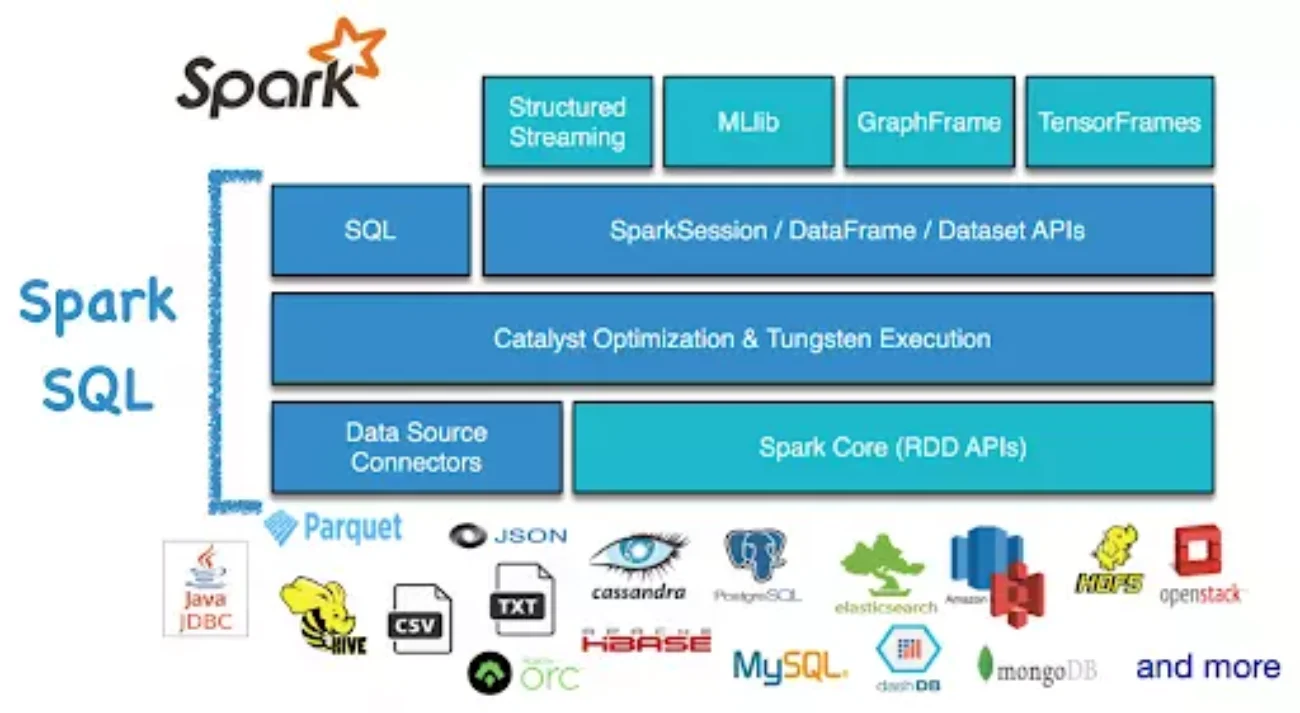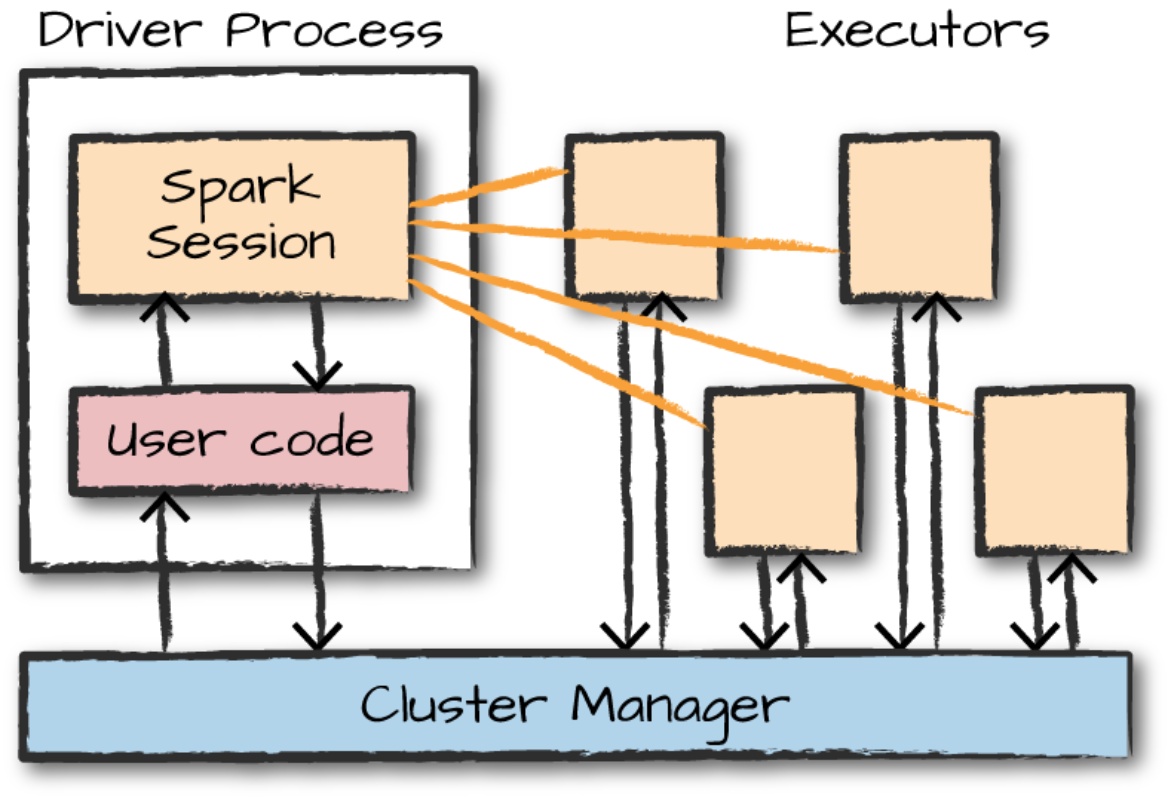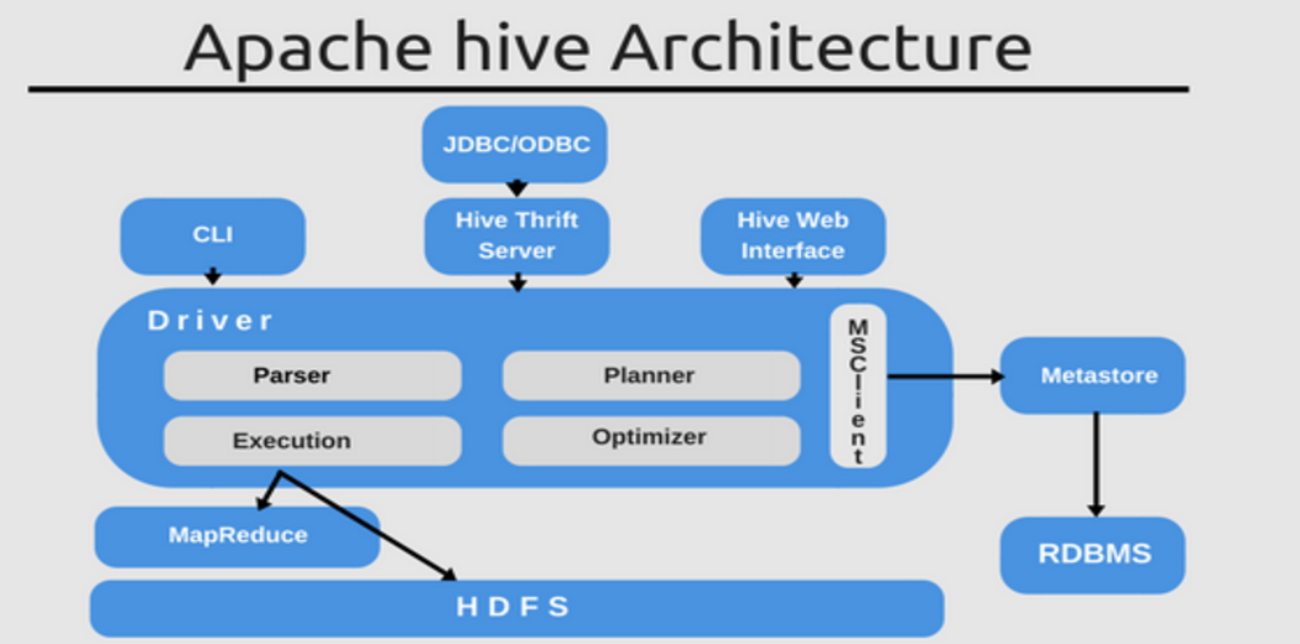
Apache Hive
Giới Thiệu Apache Hive là một hệ thống lưu trữ dữ liệu được xây dựng trên nền tảng của Hadoop, hỗ trợ phân tích các tập dữ liệu lớn được lưu trữ trong các hệ thống tệp phân tán của Hadoop (HDFS) hoặc S3 bằng cách sử dụng các truy vấn tương tự SQL. Nó lưu trữ siêu dữ liệu (metadata) của schema trong một cơ sở dữ liệu (như Apache Derby, MySQL, Postgres hoặc MariaDB) và xử lý dữ liệu từ lưu trữ kết nối (như HDFS hoặc S3). Nó cung cấp ngôn ngữ truy vấn giống SQL, HiveQL. Hive Metastore Hive metastore ghi lại tất cả thông tin cấu trúc (metadata) của một bảng Hive và các phân vùng của nó trong kho lưu trữ: Các siêu dữ liệu trong Hive metastore được lưu trữ trong một hệ quản trị cơ sở dữ liệu mã nguồn mở là Apache Derby (MySQL/Postgres/MariaDB cũng có thể được sử dụng). Hive metastore có thể có nhiều schema (cơ sở dữ liệu), và mỗi schema (cơ sở dữ liệu) có thể chứa nhiều siêu dữ liệu bảng Hive. Bảng Hive Loại bảng Hive Hive hỗ trợ hai loại bảng: Bảng Quản lý (Bảng Nội bộ) & Bảng Ngoại bộ Bảng Quản lý (Bảng Nội bộ) Bảng Quản lý: còn được gọi là bảng nội bộ, các bảng này quản lý cả dữ liệu và siêu dữ liệu trong thư mục kho lưu trữ mặc định của Hive (được chỉ định bởi hive.metastore.warehouse.dir). Bảng Ngoại bộ Bảng Ngoại bộ: các bảng này tham chiếu đến các tệp dữ liệu được lưu trữ bên ngoài Hive, thường là trong HDFS hoặc S3. Vì các tệp dữ liệu không được quản lý bởi Hive, nên việc thay đổi hoặc xóa một bảng Hive ngoại bộ không xóa dữ liệu ở dạng dưới lying. Bạn có thể cần xóa dữ liệu từ vị trí HDSF hoặc S3 phía dưới. Cách Tạo Bảng Hive Bước 1: Tạo SparkSession với cấu hình Hive pythonSao chép mãspark = SparkSession.builder \ .appName(“Hive Table Example”) \ .config(“spark.sql.warehouse.dir”, “/user/hive/warehouse”) \ .enableHiveSupport() \ .getOrCreate() Bước 2: Có hai phương pháp để tạo bảng Hive Phương pháp 1: Tạo bảng Hive bằng cách sử dụng API DataFrame với write.saveAsTable pythonSao chép mã# Bảng Quản lý (Bảng Nội bộ) df.write \ .mode(“overwrite”) \ .option(“database”, “your_database_name”) \ .partitionBy(“partition_col1”, “partition_col2”) \ .saveAsTable(“hive_table_name”) # Bảng Ngoại bộ df.write \ .mode(“overwrite”) \ .option(“database”, “your_database_name”) \ .option(“path”, “s3a://your_bucket_name/your_folder_path/your_external_table_name”) \ .partitionBy(“partition_col1”, “partition_col2”) \ .format(“parquet”) \ .saveAsTable(“hive_table_name”) Phương pháp 2: Tạo Bảng Hive bằng cách sử dụng Truy vấn SQL với spark.sql pythonSao chép mã# Bảng Quản lý (Bảng Nội bộ) spark.sql(“”” CREATE TABLE IF NOT EXISTS your_database_name.your_managed_table_name ( id INT, name STRING, age INT ) PARTITIONED BY (country STRING, city STRING) USING PARQUET “””) # Bảng Ngoại bộ spark.sql(“”” CREATE TABLE IF NOT EXISTS your_database_name.your_external_table_name ( id INT, name STRING, age INT ) PARTITIONED BY (country STRING, city STRING) STORED AS PARQUET LOCATION ‘hdfs://your_hdfs_path/your_external_table_name/’ “””) Cách chèn dữ liệu vào Bảng Hive Phương pháp 1: Ghi trực tiếp thông qua write.saveAsTable vào Bảng Hive pythonSao chép mãdf.write \ .mode(“overwrite”) \ .partitionBy(“partition_col1”, “partition_col2”) \ .format(“parquet”) \ .saveAsTable(“your_database_name.your_hive_table_name”) Phương pháp 2: Ghi vào vị trí lưu trữ dưới lying & cập nhật lại siêu dữ liệu Hive pythonSao chép mãtable_path = “s3a://your_bucket_name/your_folder_path/your_hive_table_name” df.write \ .mode(“overwrite”) \ .partitionBy(“partition_col1”, “partition_col2”) \ .parquet(table_path) spark.sql(“REFRESH TABLE your_database_name.your_hive_table_name”) spark.sql(“MSCK REPAIR your_database_name.your_hive_table_name”) Cách Xem Chi Tiết Bảng Hive Lấy thông tin chi tiết về bảng pythonSao chép mãtable_metadata = spark.sql(“DESCRIBE FORMATTED db.table_name”) table_metadata.show(truncate=False) Lấy thông tin về phân vùng của bảng pythonSao chép mãpartitions = spark.sql(“SHOW PARTITIONS db.table_name”) partitions.show(truncate=False) Đây là một cách sơ bộ để làm việc với Hive trong Spark. Có nhiều khía cạnh và tính năng hơn mà bạn có thể khám phá!