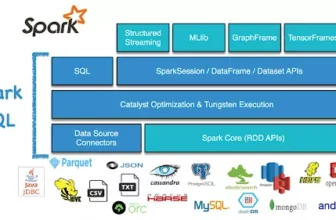
Cài đặt Cấu hình Spark
Phương pháp 1: Xác định cấu hình Spark khi tạo SparkSession thông qua .config
pythonSao chép mãspark = SparkSession \
.builder \
.appName("SparkExample") \
.config("spark.sql.warehouse.dir", "/user/hive/warehouse") \
.getOrCreate()
Nếu bạn cần thiết lập nhiều cấu hình, bạn có thể định nghĩa chúng trong một từ điển hoặc trong tệp yaml và thiết lập tương ứng thông qua một vòng lặp.
pythonSao chép mãspark = SparkSession \
.builder \
.appName("SparkExample") \
custom_spark_config = {
"spark.driver.memory": "9g",
"spark.executor.cores": "2",
"spark.executor.memory": "9g",
"spark.yarn.queue": "root.tnm.ada_analytics_tnm", # cần cập nhật với tên Queue YARN
}
# Vòng lặp để thiết lập từng cấu hình Spark trong từ điển
for key, value in custom_spark_config.items():
spark = spark.config(key, value)
spark = spark.getOrCreate() # tạo phiên Spark với các cấu hình đã chỉ định
Phương pháp 2: Để thiết lập cấu hình Spark sau khi đối tượng SparkSession đã được tạo
pythonSao chép mã# trong trường hợp này, chúng ta có "spark" là đối tượng SparkSession đã tạo
spark.conf.set("spark.sql.shuffle.partitions", "200")
Phương pháp 3: Xác định cấu hình Spark trong lệnh spark-submit, vì hai phương pháp trên được cố định và khá tĩnh, và bạn muốn có các tham số khác nhau cho các công việc khác nhau.
bashSao chép mãspark-submit --executor-memory 16G
Lấy Cấu hình Spark
pythonSao chép mãspark.conf.get("spark.executor.memory") # để kiểm tra cấu hình Spark xem nó được thiết lập đúng không
Danh sách các cấu hình
spark.memory
- (“spark.memory.offHeap.enabled”,”true”): Nếu là true, dữ liệu được lưu trữ trong bộ nhớ off-heap để tránh lưu trữ trực tiếp trên đĩa.
- (“spark.memory.offHeap.size”,”10g”): Bạn cũng có thể xác định kích thước bộ nhớ off-heap.
spark.sql
- (“spark.sql.shuffle.partitions”, “200”): Để thiết lập số lượng phân vùng đầu ra từ shuffle (mặc định là 200). Thử nghiệm với các giá trị khác nhau, bạn sẽ thấy thời gian chạy khác biệt đáng kể.
- (“spark.sql.warehouse.dir”, “/user/hive/warehouse”): Thuộc tính cấu hình này chỉ định vị trí mặc định mà Spark SQL sẽ lưu trữ bảng được quản lý trong thư mục kho dữ liệu của Hive.